一种基于深度学习的低光图像增强方法
原文 MBLLEN: Low-light Image/Video Enhancement Using CNNs
摘要
作者提出了一种基于深度学习的低光图像增强(low-light image enhancement)方法。这个问题的挑战性在于我们需要同时处理各种因素,包括亮度、对比度、伪影、噪声。为了解决这个问题,作者提出了多分支低光增强网络(MBLLEN)。它的核心思想是提取不同层次的丰富特征,通过多个子网进行增强,最后经过多分支融合得到输出图像。通过大量实验发现,作者提出的MBLLEN优于SOTA。作者还表示他们的方法可以直接扩展到处理低光视频。
介绍
人们对低光图像增强进行了大量研究。他们通常关注恢复图像的亮度和对比度,同时防止诸如颜色失真等问题。现有的方法大致可以分为两类,基于直方图均衡化的方法和基于Retinex理论的方法。前者基于直方图均衡化的思想优化像素亮度;后者恢复场景的光照图,并且相应地增强不同图像区域。
现有方法往往依赖于像素统计或视觉机制的某些假设,这些假设可能不适用于某些实际场景。其次,除了亮度/对比度优化,伪影和噪声也要小心地处理。
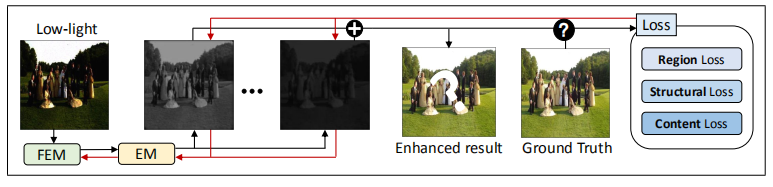
本文提出了一种新的低光图像增强方法。该方法的核心是全卷积神经网络,即多分支低光增强网络(MBLLEN)。MBLLEN包含3个模块,分别是特征提取模块(FEM)、增强模块(EM)和融合模块(FM)。它的思想是:1)利用FEM提取不同层次的丰富特征;2)使用EM分别对不同层次的特征进行增强;3)使用FM融合多分支,得到最终的输出。通过这种方式,MBLLEN能够从各个方面提高图像质量。
网络结构
如图所示, MBLLEN由3个模块组成:特征提取模块(FEM)、增强模块(EM)和融合模块(FM)。
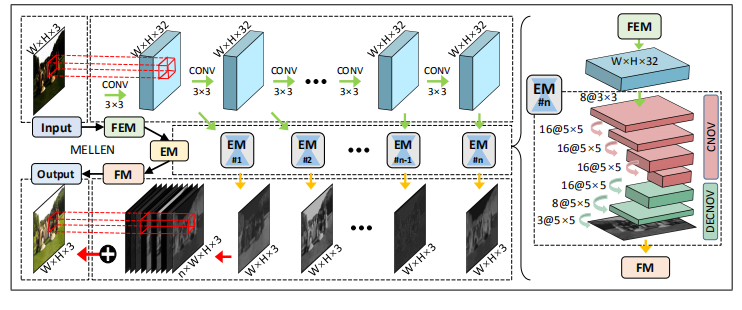
FEM 它是一个具有10个卷积层的单数据流网络,每个卷积层使用大小为3×3、步长为1的卷积核和ReLU函数,并且没有池化运算。第一层的输入是低光图像。每一层的输出既是下一层的输入,也是EM相应子网的输入。
EM 它包含多个子网,子网的数目等于FEM的层数。子网的输入是FEM某一层的输出,并且输出是与原始低光图像大小相同的彩色图像。每个子网都是对称结构,先进行卷积,然后进行反卷积。第一个卷积层使用8个大小为3×3,步长为1的卷积核和ReLU函数。然后是三个卷积层和三个反卷积层,使用大小为5× 5、步长为1的卷积核和ReLU函数,核数分别为16、16、16、16、8和3。注意,所有子网都是同时、独立训练,没有共享任何学习到的参数。
FM 它接收所有EM子网的输出,生成最终图像。作者将EM的所有输出排列在颜色通道维度中,然后使用一个1× 1的卷积核来融合它们。
该方法经过简单修改后可以用于处理视频增强。1) 让FEM使用3D卷积替换2D卷积,即使用16个大小为3×3×3的卷积核。第一层的输入是31帧的低光彩色视频。每层输出的前三个维度被发送到EM,其余维度作为下一个卷积层的输入。2) EM修改为执行3D卷积。3) FM使用原始的低光视频作为融合的额外输入。
损失函数
实验细节
Our implementation is done with Keras and Tensorflflow. The proposed MBLLEN can be quickly converged after being trained for 5000 mini-batches on a Titan-X GPU with a set of 16925 images from the PASCAL VOC dataset. We use mini-batches of 24 patches of size 256×256×3. The input image values should be scaled to [0,1].
In terms of designing the context loss, we test each convolutional layer of VGG-19. From the fourth convolution block, the enhancement effect decreases slightly. On the other hand, with deeper layers, the feature map size decreases, which increases the computational effificiency. As a trade-off, we use the output of the fourth convolutional layer of the third block of VGG as the context loss extraction layer.
In the experiment, training is done using the ADAM optimizer with a learning rate of α = 0.002, β1 = 0.9, β2 = 0.999 and ε = 1008 . We also use the learning rate decay strategy, which reduces the learning rate to 95% before the next epoch.
实验结果
